数据分析
从一堆看似杂乱的数据中,通过数据清洗、分析、可视化等手段,找出有价值的信息和结论,从而帮我们解决实际的问题(如:用户订单数据的分析、电影榜单数据分析、学校学生成绩分析等)。

环境准备
Jupyter Notebook
Jupyter Notebook是一个基于Web网页的、交互式的编程笔记本,让你可以把代码、运行结果、图表和笔记全部都放在一个文件里(在数据分析、机器学习、教学和科研等领域的数据实验室)


Pandas基础
Pandas介绍
- Pandas是一个功能强大的结构化数据分析的工具集,底层是基于Numpy构建的,无论是在数据分析领域、还是大数据开发场景中都有显著的优势。
- 官网:https://pandas.pydata.org
- 核心:DataFrame(是一个表格型的数据结构,就像一张Excel表格,有行有列;)、Series(是一列数据,就像DataFrame中的单独一列;)
- 构建DataFrame的方式有很多种,主要方式如下
Datafranme
- 构成DataFrame的方式有很多种,具体方式如下
jsx
import pandas as pd
# 创建DataFrame
df1 = pd.DataFrame([
{'姓名': '王林', '语文': 80, '英语': 90, '数学': 88},
{'姓名': '李慕婉', '语文': 92, '英语': 81, '数学': 93},
{'姓名': '十三', '语文': 87, '英语': 83, '数学': 78}
])
df2 = pd.DataFrame({
'姓名': ['王林', '李慕婉', '十三'],
'语文': [80, 92, 87],
'英语': [90, 81, 83],
'数学': [88, 93, 78]
})
df3 = pd.DataFrame([
['王林', 80, 90, 88],
['李慕婉', 92, 81, 93],
['十三', 87, 83, 78]
], columns=['Name', 'Chinese', 'English', 'Math'])
df4 = pd.DataFrame([
('王林', 80, 90, 88),
('李慕婉', 92, 81, 93),
('十三', 87, 83, 78)
], columns=['姓名', '语文', '英语', '数学'], index=['a', 'b', 'c'])
# DataFrame 常见属性 - index , columns , values, size , dtypes , shape
# df4.index.tolist() # index : 索引
# df4.columns.tolist() # columns : 列名
# df4.values.tolist() # values : 值
# df4.size # size : 元素个数
# df4.dtypes # dtypes : 数据类型
df4.shape # shape : 维度(行, 列)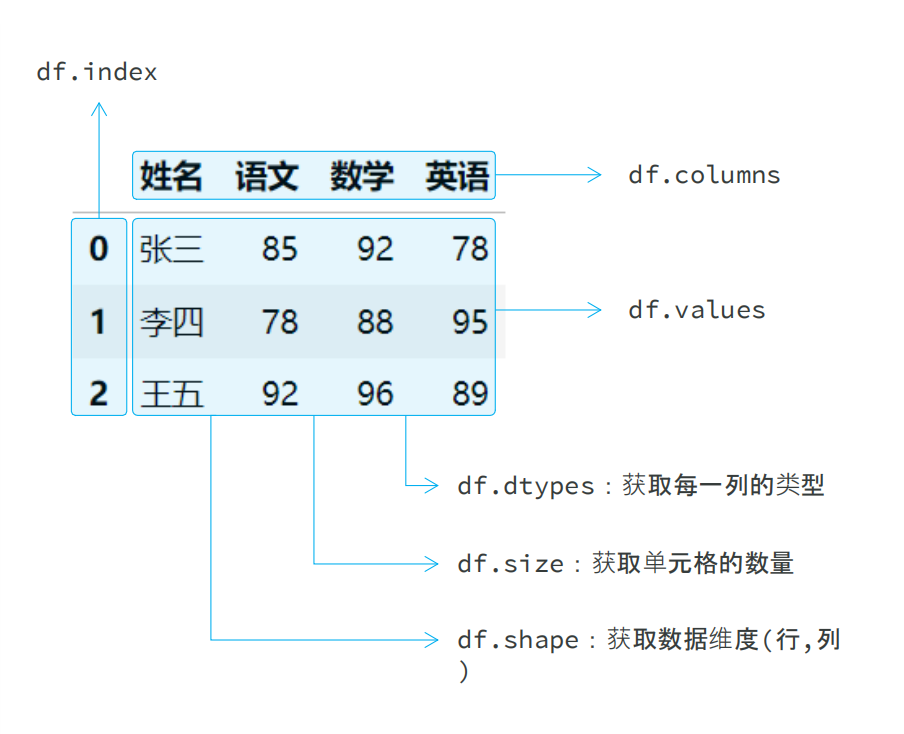
Series
- 构建Series的方式有很多种,主要方式如下
jsx
s1 = pd.Series([10, 20, 30, 40, 50])
s2 = pd.Series((10, 20, 30, 40, 50), index=['a', 'b', 'c', 'd', 'e'])
s3 = pd.Series({'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50})
s4 = df4['语文']
print(s4)
# Series 常见属性 - index , values, size , dtype , shape
print(s3.index.tolist()) # index : 索引
print(s3.values.tolist())# values : 值
s3.size # size : 元素个数
s3.dtype # dtype : 数据类型
s3.shape # shape : 维度(行, )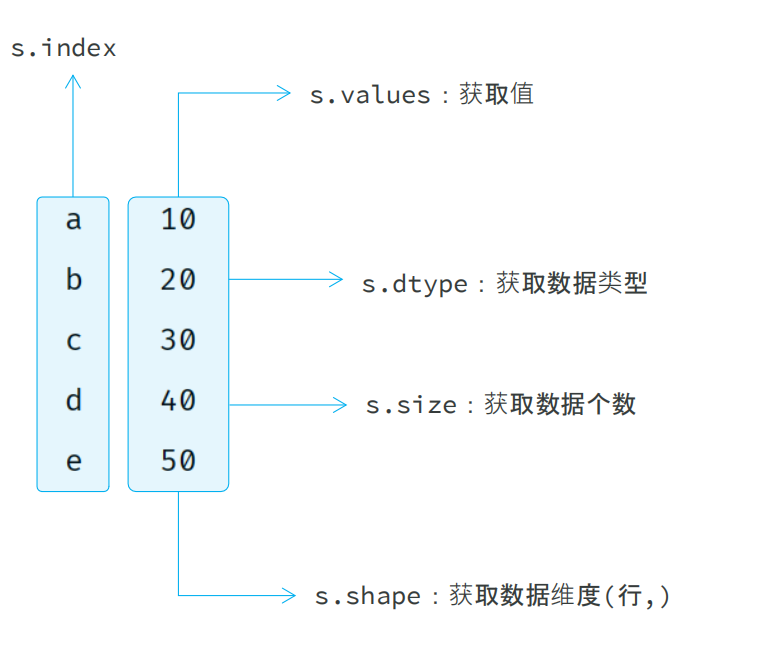
数据读取和写入
- 基于Pandas中提供的API,可以很方便的各类数据文件(csv、Excel、数据库、网络数据等)的读取和写入。

jsx
import pandas as pd
# 读取数据 --> read_csv usercols -->选择需要的列
df = pd.read_csv('data/sales.csv', usecols=['订单号', '产品类别', '产品名称', '销售数量', '单价'])
# 数据处理
df['销售金额'] = df['销售数量'] * df['单价']
# 写入数据 --> to_csv --- index=False: 不写入索引列
df.to_csv('data/sales_01.csv', index=False)读取数据和写入数据分别调用什么方法?
read_xxx,比如:read_csv, read_excel • to_xxx,比如:to_csv, to_excel
数据的查看、选择及过滤

数据查看
jsx
# 数据查看 --> head , tail , describe , info , shape , columns
df1 = pd.read_csv('data/sales.csv', usecols=['订单号', '产品类别', '产品名称', '销售数量', '单价'])
# df1.head(10) # 显示前10行数据
# df1.tail(10) # 显示最后10行数据
# df1.describe() # 显示数据统计信息
# df1.info() # 显示数据信息(列名, 非空计数, 数据类型等)
# df1.shape # 显示数据行数和列数
df1.columns # 显示列名数据选择
jsx
# 数据选择
df2 = pd.read_csv('data/sales.csv', usecols=['订单号', '产品类别', '产品名称', '销售数量', '单价'], index_col='订单号')
# 1. 选择列
# 1.1 单列
# df2['产品名称']
# df2.产品名称
# 1.2 多列
# df2[['产品名称', '单价']]
# df2[['产品类别', '产品名称', '单价']]
# 2. 选择行 - iloc , loc
# 2.1 iloc ----> 基于行号选择行 (不包含结束位置) , 语法: df.iloc[start:stop:step]
# df2.iloc[0:5:1]
# df2.iloc[0:5]
# 2.2 loc ----> 基于行索引选择行 (包含结束位置) , 语法: df.loc[start:stop:step]
df2.loc[6805677496:5888085066:2]数据的过滤
jsx
df3 = pd.read_csv('data/sales.csv')
# 配置项, 展示所有的数据
# pd.set_option('display.max_rows', None)
# 数据过滤 ---> df[filter]
# 1. 获取 销售数量 >= 10 的订单数据
df3[df3['销售数量'] >= 10]
# 2. 获取产品类别为 食品 或 图书 的订单数据
df3[df3['产品类别'].isin(['食品', '图书'])]
# 3. 获取 单价在100-200之间 的订单数据 ---> 范围: between ---> 默认包含边界 (inclusive="left")
df3[df3['单价'].between(79, 199)]
# 4. 获取 销售数量 >= 8 , 并且 单价 >= 100 的订单数据 ----> 多条件(并且: & , 或者: |)
df3[(df3['销售数量'] >= 8) & (df3['单价'] >= 100)]
# 5. 获取 产品类别为 服装/食品 , 支付方式为 支付宝/微信支付 的订单数据
df3[(df3['产品类别'].isin(['服装', '食品'])) & (df3['支付方式'].isin(['支付宝', '微信支付']))]数据的清洗
- 数据清洗是指发现并纠正数据中可识别的错误的过程,包括处理缺失值、重复值、异常值,统一数据格式,保证数据的一致性。

缺失值处理
jsx
import pandas as pd
# 设置最大显示行数(默认10行)
pd.set_option('display.max_rows', 30)
# 1. 读取数据
df = pd.read_csv('Data/sales.csv')
# 2. 数据清洗
# 2.1 缺失值处理
# df.isnull() # 查看缺失值
# 2.1.1 删除缺失值
# df.dropna() # 删除缺失值所在行
# df = df.dropna(axis=1) # 删除缺失值所在列
# df
# 2.1.2 填充缺失值
# df.fillna('--') # 填充缺失值
# df.ffill() # 填充缺失值, 填充上一行数据
# df.bfill() # 填充缺失值, 填充下一行数据重复值处理
jsx
# 2.2 重复值处理
# 2.2.1 查看重复值
df.duplicated() # 查看重复值(所有的列的数据都重复)
df.duplicated(subset=['订单号']) # 查看重复值(指定列的数据重复)
# 2.2.2 删除重复值
df.drop_duplicates(subset=['订单号']) # keep='last' 保留重复值最后一行; keep='first' 保留重复值第一行;异常值处理
jsx
# 2.3 异常值处理
# 2.3.1 查看异常值
df[df['单价'] <0]
# 2.3.2 删除异常值
df.drop(df[df['单价'] <0].index)
# 2.3.3 修复异常值
df['单价'] = df['单价'].abs() # 绝对值
df数据格式处理
jsx
# 2.4 数据格式处理
df['订单日期'] = df['订单日期'].str.replace('/', '-')
df数据排序与分组
排序
在进行数据排序时,有两种排序方式,分别是:升序和降序。而基于Pandas进行数据排序时,是可以按照多个列进行排序的。

jsx
import pandas as pd
# 1. 读取数据
df = pd.read_csv('data/sales.csv', nrows=10)
# 2. 排序
# 2.1 根据 销售数量 倒序排序
# df.sort_values('销售数量', ascending=False)
# 2.2 根据 单价 升序排序
df.sort_values('单价', ascending=True)
df.sort_values('单价')
# 2.3 根据 单价 升序排序, 价格一样, 再根据 销售数量 倒序排序
df.sort_values(['单价', '销售数量'], ascending=[True, False])
# df.sort_values(['单价', '销售数量'], ascending=True)分组
分组操作就是把数据按照某个特征分成不同的组,然后对每个组分别进行统计计算。

jsx
df = pd.read_csv('data/sales.csv', nrows=20)
df['销售金额'] = df['单价'] * df['销售数量']
# 3. 分组
# 3.1 根据 产品类别 分组, 统计各个类别的 订单数量 - count
df.groupby('产品类别')['订单号'].count()
# 3.2 根据 产品类别 分组, 统计各个类别的 销售数量 之和 - sum
df.groupby('产品类别')['销售数量'].sum()
# 3.3 根据 产品类别 分组, 统计各个类别的 销售金额 之和 - sum
df.groupby('产品类别')['销售金额'].sum()
# 3.4 根据 产品类别 分组, 统计各个类别的最低商品 单价 - min
df.groupby('产品类别')['单价'].min()
# 3.5 根据 产品类别 分组, 统计各个类别的最高商品 单价 - max
df.groupby('产品类别')['单价'].max()
# 3.6 根据 产品类别 分组, 统计各个类别的平均商品 单价 - mean
df.groupby('产品类别')['单价'].mean()
# 3.7 根据 产品类别 分组, 统计各个类别的商品的 平均单价、最高单价、最低单价 - agg
df.groupby('产品类别')['单价'].agg(['mean', 'max', 'min'])
df.groupby('产品类别').agg({'单价': ['mean', 'max', 'min']})
# 3.8 根据 产品类别 分组, 统计各个类别的商品的 销售数量 之和,销售金额 之和,平均 单价
df.groupby('产品类别').agg({'销售数量': 'sum', '销售金额': 'sum', '单价': 'mean'})Matplotlib基础
Matplotlib初识
- Matplotlib是一个功能强大的数据可视化开源Python库,也是Python中使用的最多的图形绘图库,可以创建静态、动态、交互式的图表。
- 官网:https://matplotlib.org
- 安装:pip install matplotlib
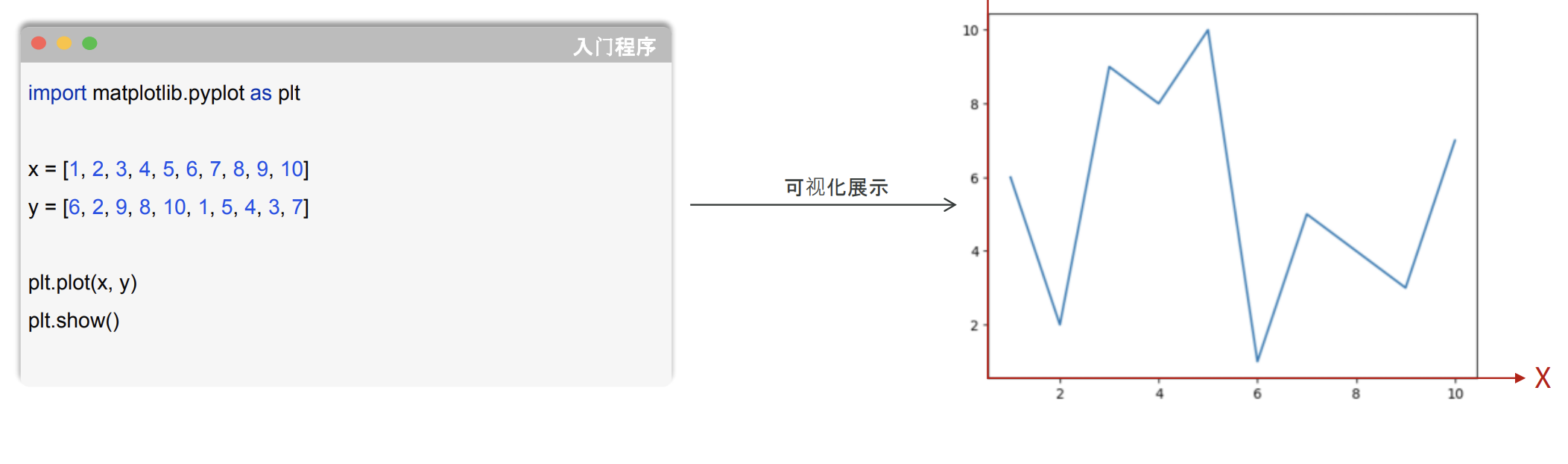 注意: x轴的数据数量与y轴中的数据数量要一致
注意: x轴的数据数量与y轴中的数据数量要一致
Matplotlib图表详解

jsx
import matplotlib.pyplot as plt
import random
# 展示中文
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 设置中文字体为黑体
x = [i for i in range(1, 25)]
y_bj = [random.randint(10,15) for i in x]
y_xa = [random.randint(13,18) for i in x]
plt.figure(figsize=(10, 5)) # 设置画布大小, 宽, 高
plt.plot(x, y_bj, label='北京') # 折线图 -> 如果没有画布, 会自动创建一个画布
plt.plot(x, y_xa, label='西安')
# 设置折线图的详细信息
plt.title('气温变化折线图', fontsize=15) # 标题
plt.xlabel('时间') # x轴标签
plt.ylabel('温度') # y轴标签
# plt.xticks(x[::2])
# plt.xticks(x[1::2])
plt.xticks(x) # x轴刻度
y_ticks = [i for i in range(5,21)]
plt.yticks(y_ticks) # y轴刻度
plt.grid(linestyle='--', alpha=0.3) # 显示网格
plt.legend(loc='upper right') # 显示图例
plt.show() # 显示图表